Nrishinghananda Roy
Architecting highly reliable infrastructure to accelerate product delivery.
Running production cloud environments for startups across Europe and India. All remote.
I build Kubernetes clusters, resilient CI/CD pipelines, and cloud infrastructure on AWS. By integrating Terraform with modern GitOps workflows, I do not just maintain infrastructure; I engineer it for ultimate reliability. The goal is zero configuration drift, zero downtime, and systems so reliable they become invisible.

What I can do for you
Shipping software is straightforward until the infrastructure becomes a bottleneck. Deployments that break production. Staging environments that drift from reality. Systems that fail on a Friday night with no clear path to recovery. When reliability suffers, it becomes an expensive business problem.
I build and operate the highly reliable infrastructure that stops these problems from reaching your users.
By implementing Infrastructure as Code with Terraform and orchestrating container workloads through Kubernetes, I ensure your environments are immutable, infinitely reproducible, and capable of autonomous scaling.
This means your team ships faster and safer. I automate robust CI/CD pipelines using GitHub Actions and orchestrate GitOps workflows via ArgoCD, making deployments predictable and rollbacks instant.
I don't just string tools together. I write custom automation that eliminates manual toil, and I implement proactive observability with Prometheus and Grafana so I never have to wait for an outage to tell me something is wrong.
If your infrastructure is slowing your product cycle, or if you need a scalable cloud foundation built for absolute reliability from day one, that is exactly what I solve.
What I have shipped
A 15x performance improvement on a live system.
At Codefy GmbH in Germany, a third-party Java microservice was adding over 3 seconds of latency to every API request. I read the codebase, understood exactly what it was doing, and rebuilt it from scratch in Rust (Axum) and PostgreSQL. Response times dropped to under 200 milliseconds under production load.
I also built automated document processing pipelines in Rust for their legal workflows, reducing significant manual effort. The harder part was understanding unfamiliar distributed systems well enough to replicate their behavior perfectly without breaking anything downstream.
Scale & Production Cloud Infrastructure.
At Dhiway in India, I provisioned and managed production cloud infrastructure on AWS utilizing Terraform for consistent environment replication.
I also configured robust monitoring and telemetry for 60+ distributed nodes using Prometheus and Grafana to precisely track system performance and network latency.
Technical Writing & Security Deep Dives
Most companies discover a security problem after it has already caused damage. A compromised environment, stolen credentials, a breach that nobody noticed for weeks.
I strongly believe that security must be built into infrastructure from day one, not retrofitted after an incident.
Below is a deep-dive into a sophisticated supply-chain attack I recently reverse-engineered, highlighting exactly why securing deployment pipelines and container environments is an absolute baseline requirement for modern startups.
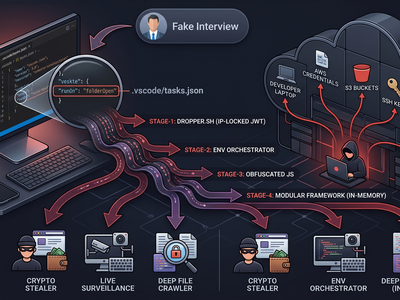
The Fake Interview Malware: Reverse Engineering a VS Code Exploit
A technical teardown of a developer supply chain attack. Learn how attackers use fake job interviews and VS Code tasks.json to deploy zero-c…
Read full research →Let's Talk
I am available for remote DevOps Engineering and Cloud Engineering work.
While taking on new work I am also deepening my Kubernetes expertise, building production systems, solving real operational problems.
If you have infrastructure that needs someone to take ownership of it and deliver on-time, I am the right person to talk to.